01
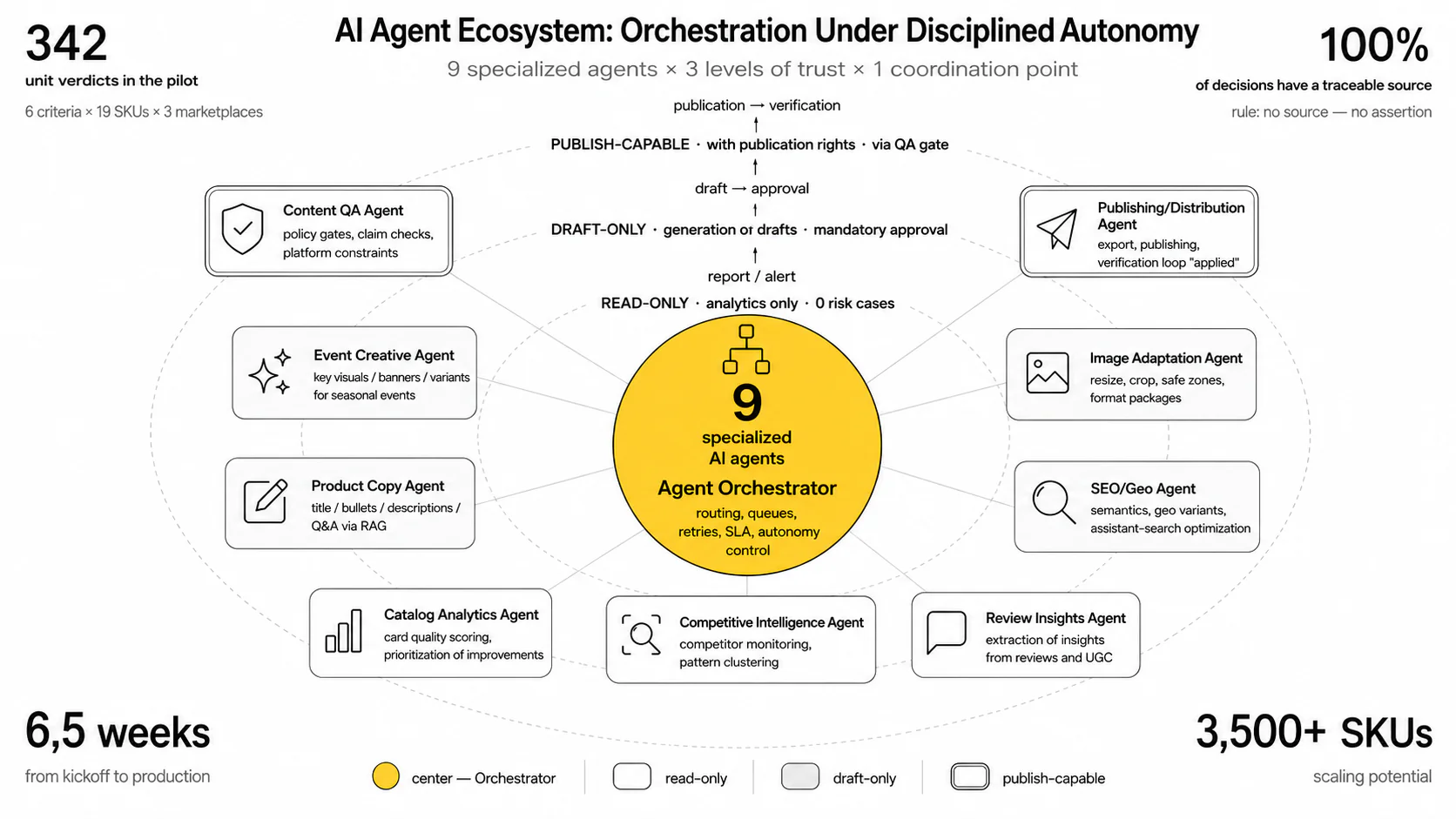
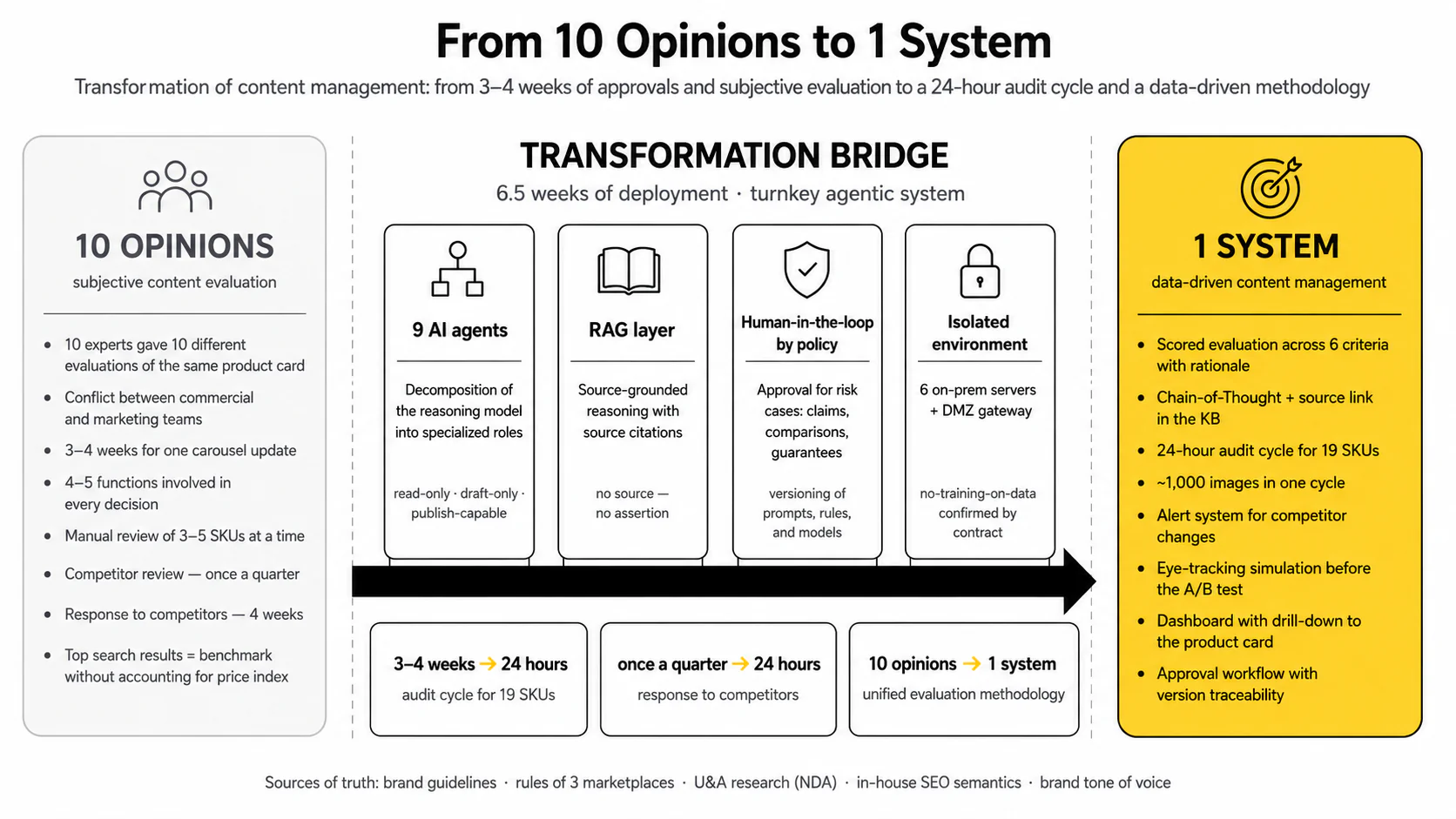
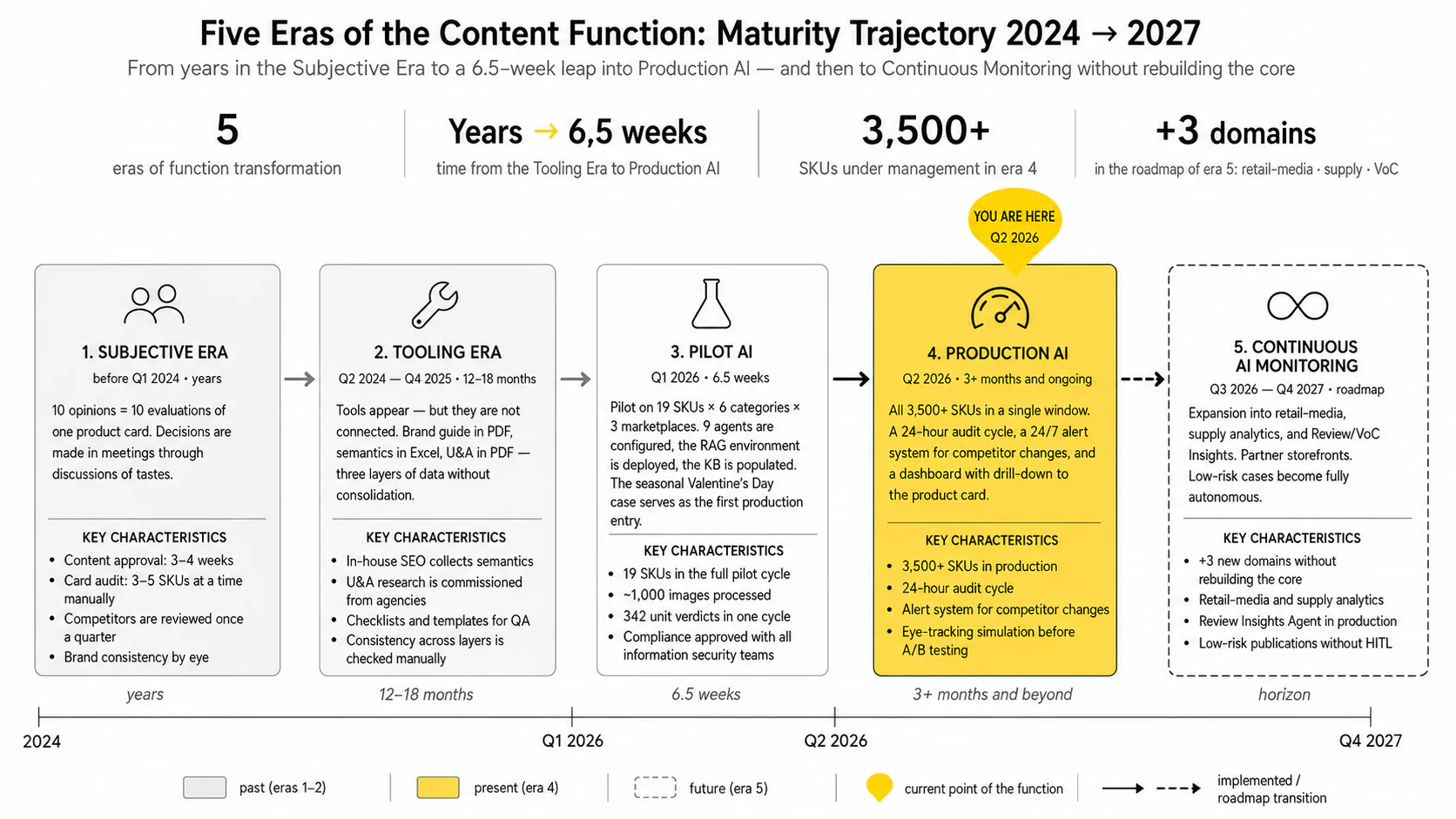
9 agents instead of 10 opinions
The reasoning layer is split into 9 specialized agents (Creative, Copy, SEO/GEO, QA, Analytics, Competitive, Publishing, and others) with autonomy policies ranging from "read-only" to "with publication rights." The orchestrator assembles verdicts into a report: 6 criteria × 19 SKUs × 3 marketplaces = 342 verdicts, each with a 3–5 sentence rationale and source reference.